
Giải Mã Chaos Engineering: Biến Hệ Thống 'Bất Tử' Trong Kỷ Nguyên Cloud-Native
0
Chaos Engineering cho Microservices: Tăng Cường Độ Bền Hệ Thống Phân Tán
Mở Đầu
Trong bối cảnh các ứng dụng hiện đại ngày càng chuyển sang kiến trúc microservices, sử dụng Kubernetes và các service mesh như Istio, đảm bảo độ bền (resilience) của hệ thống trở thành một thách thức lớn. Việc phân tán dịch vụ tạo ra nhiều nguy cơ lỗi mới, đòi hỏi phải kiểm thử chủ động để nâng cao tính khả dụng của hệ thống.
Chaos Engineering (kỹ thuật hỗn loạn) giúp các tổ chức phát hiện và khắc phục các điểm yếu trước khi chúng gây ra sự cố trong môi trường sản xuất. Việc chủ động tạo ra các lỗi có kiểm soát giúp phân tích hành vi của hệ thống và cải thiện độ tin cậy tổng thể. Bài viết này sẽ hướng dẫn cách triển khai Chaos Engineering cho các ứng dụng Java (Spring Boot), Node.js, môi trường Kubernetes và Istio bằng các công cụ như Chaos Toolkit và Chaos Monkey. Chúng ta cũng sẽ đề cập các phương pháp tiêm lỗi trên Kubernetes, Istio nhằm cải thiện khả năng chịu lỗi của ứng dụng trong hệ sinh thái đa đám mây.
Chaos Engineering Là Gì?
Chaos Engineering là một phương pháp luận nhằm tìm kiếm các điểm yếu tiềm ẩn trong hệ thống phân tán thông qua việc mô phỏng các thất bại thực tế. Mục tiêu là tăng cường sức chịu đựng của ứng dụng bằng cách chạy các thí nghiệm có kiểm soát, giúp đội ngũ phát triển:
- Mô phỏng sự cố tại một khu vực hoặc trung tâm dữ liệu.
- Tiêm độ trễ (latency) giữa các dịch vụ.
- Đánh giá ảnh hưởng khi CPU bị tối đa hóa.
- Tạo lỗi hệ thống tập tin và I/O.
- Thử nghiệm các tình huống khi phụ thuộc bên ngoài không khả dụng.
- Quan sát tác động lan tỏa đến các microservices khác.
Bằng cách áp dụng Chaos Engineering, tổ chức có thể phát hiện sớm các điểm yếu, giảm thời gian ngừng hoạt động, và cải thiện khả năng phục hồi khi có sự cố xảy ra.
Chu Trình Vòng Đời Chaos Engineering
Quá trình thực hiện các thí nghiệm Chaos Engineering được thực hiện theo vòng đời có cấu trúc như hình dưới:
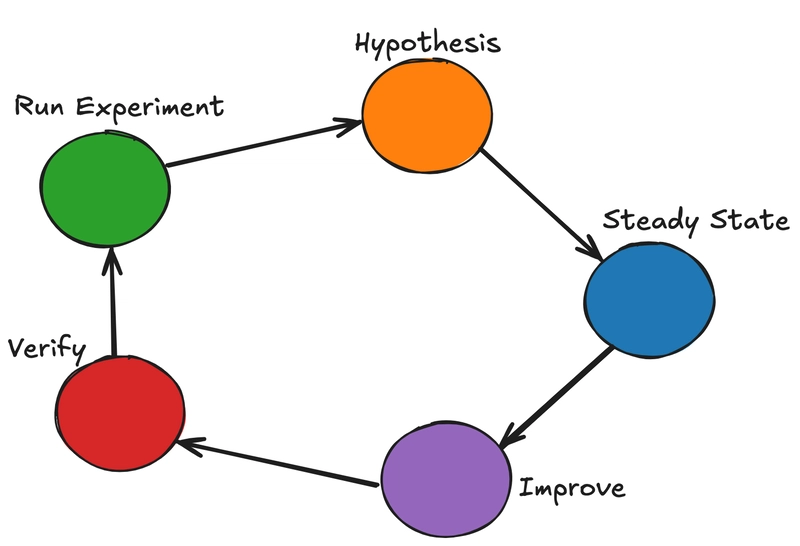
Hình 1: Chu trình vòng đời Chaos Engineering giúp cải thiện độ bền hệ thống bằng thử nghiệm liên tục.
Các bước gồm:
- Định nghĩa giả thuyết trạng thái ổn định (steady-state hypothesis).
- Thiết kế thí nghiệm mô phỏng thất bại.
- Thực thi thí nghiệm và thu thập dữ liệu.
- Phân tích kết quả.
- Học hỏi và triển khai cải tiến dựa trên kết quả.
Chaos Toolkit và Chaos Monkey: So Sánh Các Công Cụ Chính
Chaos Toolkit
- Phù hợp với môi trường Kubernetes.
- Hỗ trợ kiểm thử đa đám mây và đa ngôn ngữ.
- Cho phép định nghĩa các kịch bản thiệt hại (failures) tùy chỉnh trên các hệ thống phân tán.
Chaos Monkey
- Tập trung kiểm thử ứng dụng Java (Spring Boot).
- Tiêm lỗi mức ứng dụng như trễ phương thức, phát sinh ngoại lệ.
- Giải pháp nhẹ, tích hợp sẵn cho hệ sinh thái Java microservices.
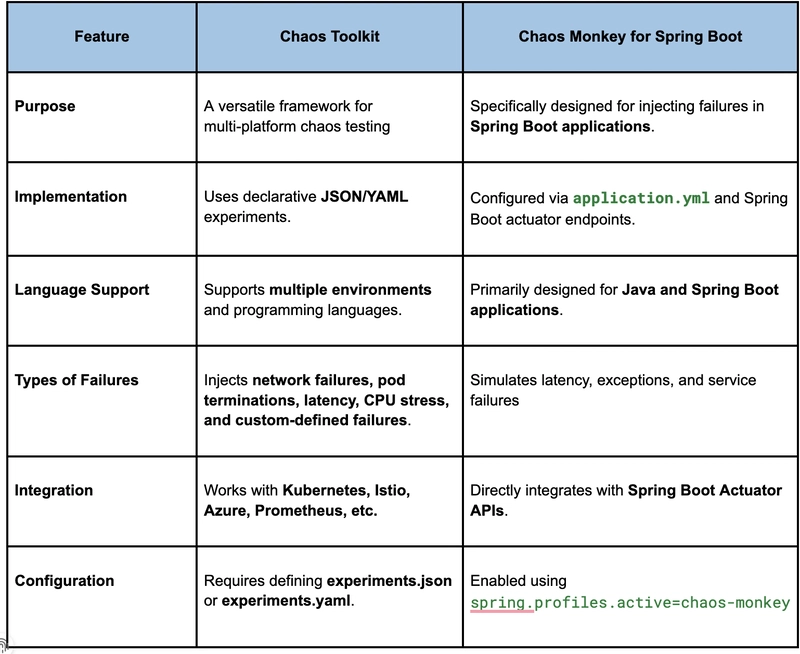
Hình 2: Sự khác biệt giữa Chaos Toolkit và Chaos Monkey.
Triển Khai Chaos Engineering Cho Java (Spring Boot)
Cách Thức Hoạt Động của Chaos Monkey cho Spring Boot
Chaos Monkey liên tục theo dõi các lớp trong ứng dụng Spring Boot bao gồm
@Controller , @Service , @Repository , thông qua các watcher tương ứng. Dựa vào các watcher này, Chaos Monkey có thể tạo ra các loại tấn công như:- Latency Assault: Làm chậm xử lý yêu cầu.
- Exception Assault: Inject ngoại lệ ngẫu nhiên vào các phương thức.
- KillApp Assault: Giả lập crash toàn bộ ứng dụng.
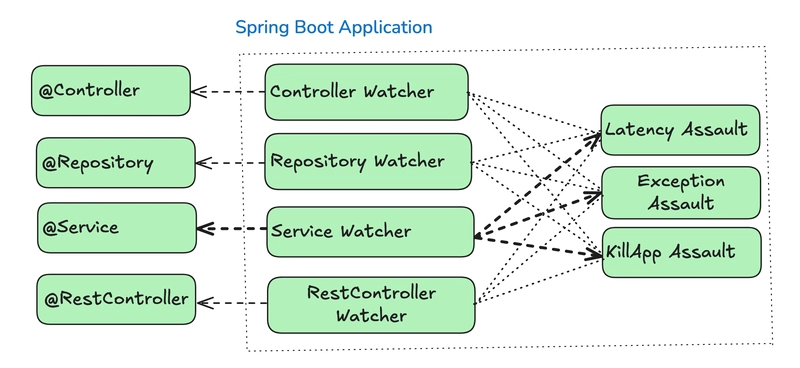
Hình 3: Mức độ tiêm lỗi của Chaos Monkey trên các lớp ứng dụng Spring Boot.
Cài Đặt Chaos Monkey trong Spring Boot
Cấu hình
application.yml :Chạy Chaos Monkey
- Khởi động ứng dụng với profile chaos-monkey:
- Kích hoạt tấn công thủ công qua Actuator:
- Cấu hình động các kiểu tấn công:
Lưu ý: Các assaults (tấn công) có thể được bật/tắt dynamic thông qua API Actuator cho phép kiểm soát linh hoạt thí nghiệm.
Chaos Engineering Trong Node.js: Chaos Monkey và Chaos Toolkit
Chaos Monkey Cho Node.js
- Thư viện phổ biến: chaos-monkey trên NPM
Cài Đặt
Ví Dụ Cơ Bản
Tính năng:
- Tiêm trễ ngẫu nhiên.
- Phát sinh lỗi ngoại lệ.
- Giả lập lỗi mạng.
Cấu Hình Để Kiểm Soát Thí Nghiệm
chaosMonkey.config.js :Trong
server.js :Chaos Toolkit Cho Node.js
Có thể dùng Chaos Toolkit để tiêm lỗi vào dịch vụ Node.js thông qua các file experiment JSON/YAML tương tự Kubernetes.
Ví dụ tiêm độ trễ bằng Chaos Toolkit:
Chạy thí nghiệm và báo cáo:
Chaos Experiments trên Kubernetes và Multi-Cloud
Tiêm Lỗi Pod
Thí nghiệm “pod kill” giúp kiểm chứng khả năng hệ thống sống sót khi một pod bị tiêu diệt đột ngột.
Ví dụ experiment JSON:
Chạy thí nghiệm:
Tạo báo cáo:
Rollback khi cần:
Tiêm Độ Trễ Khu Vực Qua Istio
Ví dụ experiment tiêm độ trễ 5 giây trên Istio Virtual Service:
Thực thi và xuất báo cáo tương tự.
Các Tình Huống Nâng Cao Khác với Chaos Toolkit
- Tạo stress CPU/MEM trên pod.
- Tắt/bỏ Database instance.
- Partition mạng giữa các dịch vụ.
- Thu nhỏ quy mô dịch vụ để test auto-scaling.
- Thí nghiệm theo thời gian cao điểm.
Những tình huống thực tiễn này giúp phát hiện điểm yếu trong kiến trúc phân tán.
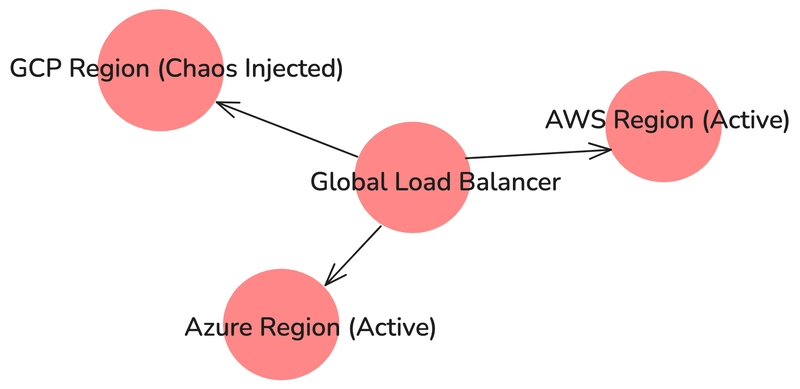
Hình 4: Kỹ thuật Chaos Engineering đa đám mây, mô phỏng lỗi vùng (region) trên AWS, Azure, GCP.
Tích Hợp Chaos Engineering Vào CI/CD Pipeline
Tại Sao Nên Tích Hợp?
- Tự động hóa kiểm thử độ bền trong quá trình triển khai.
- Phát hiện bottlenecks trước khi lên môi trường production.
- Đảm bảo hệ thống có thể tự hồi phục.
- Giảm MTTR bằng cách dựng các tình huống lỗi thực tế.
Quy Trình Tiêu Biểu
- Developer commit code.
- Build và deploy tự động trên Kubernetes.
- Chạy thí nghiệm chaos tự động.
- Quan sát và ghi nhận metrics bằng Prometheus, Datadog.
- Kiểm tra sức khỏe dịch vụ.
- Tiến hành rollback nếu có lỗi vượt ngưỡng.
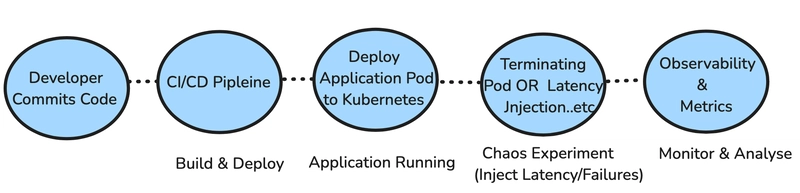
Hình 5: Tích hợp Chaos Engineering vào CI/CD bằng Kubernetes và Istio.
Ví Dụ GitHub Actions Tự Động Thí Nghiệm Chaos
Pipeline trên đảm bảo rằng thí nghiệm chaos được chạy mỗi lần có đẩy code mới, giúp giảm thiểu khả năng phát hành mã lỗi vào production.
Xác Định Kết Quả Sau Khi Chạy Thí Nghiệm
Tạo báo cáo kiểm thử:
Phân tích:
- Nếu hệ thống duy trì trạng thái ổn định → mềm có độ bền tốt.
- Phát hiện bất thường → dùng logs, monitoring công cụ để debug.
- Nếu sự cố lan rộng → cần điều chỉnh kiến trúc, thêm circuit breaker, hay tối ưu auto-scaling.
Best Practices Khi Thực Hiện Chaos Experiments
- Bắt đầu với giả thuyết trạng thái ổn định rõ ràng.
- Triển khai lỗi với mức độ thấp (ví dụ: trễ 100ms) trước khi tăng tính nghiêm trọng.
- Theo dõi chặt chẽ thông số hệ thống bằng Grafana & Prometheus.
- Kích hoạt tự động rollback để tránh gây sự cố kéo dài.
- Tăng dần mức độ “hỗn loạn” theo từng bước.
Việc vận hành thí nghiệm một cách kiểm soát sẽ giúp giảm thiểu rủi ro và nâng cao hiệu quả của quá trình cải thiện độ bền.
Kết Luận
Chaos Engineering là một phần không thể thiếu trong hệ sinh thái đám mây, Kubernetes và service mesh hiện đại. Từ Java với Chaos Monkey đến các kịch bản phức tạp trên Kubernetes và Istio bằng Chaos Toolkit, việc tiêm lỗi có kiểm soát giúp:
- Khám phá kịp thời các điểm yếu trong kiến trúc phân tán.
- Cải thiện khả năng chịu lỗi và tự phục hồi của dịch vụ.
- Hỗ trợ triển khai CI/CD với khả năng kiểm thử độ bền tự động.
- Đảm bảo hệ thống vận hành ổn định, giảm thiểu downtime trong môi trường production đa đám mây.
Hãy bắt đầu tích hợp Chaos Engineering vào quy trình phát triển của bạn để xây dựng hệ thống bền bỉ và linh hoạt. Happy Chaos Engineering!
Tham Khảo
- Principles of Chaos Engineering – Nguyên tắc cốt lõi của Chaos Engineering.
- Chaos Monkey for Spring Boot Documentation – Hướng dẫn triển khai Chaos Monkey trong Spring Boot.
- Spring Boot Actuator Reference – Tài liệu chính thức về Spring Boot Actuator.
- Chaos Monkey for Node.js (NPM Package) – Thư viện inject lỗi cho Node.js.
- Chaos Toolkit Official Documentation – Hướng dẫn sử dụng Chaos Toolkit.
- Chaos Toolkit GitHub Repository – Mã nguồn và đóng góp.
- Chaos Toolkit Kubernetes Integration – Hướng dẫn tiêm lỗi trên Kubernetes.
- Bài gốc trên DZone
Loading...