
Xây Dựng Ứng Dụng RAG Đa Phương Thức với MongoDB Atlas Vector Search và Voyage AI
0
Xây Dựng Ứng Dụng RAG Đa Phương Thức Với Mô Hình Nhúng Đa Phương Thức và LLM Hiện Đại
Mở Đầu
Trong thời đại internet phát triển mạnh mẽ, nội dung trực tuyến đa dạng về phương thức truyền tải như văn bản, hình ảnh, âm thanh và video. Tuy nhiên, các ứng dụng AI dựa trên mô hình ngôn ngữ lớn (LLM) trong những năm gần đây chủ yếu tập trung xử lý dữ liệu văn bản do hạn chế của các mô hình nhúng chỉ hỗ trợ văn bản. Điều này đang thay đổi nhanh chóng khi các mô hình như Gemini 2.0 và GPT-4o có thể xử lý đa dạng các loại dữ liệu khác nhau, bao gồm hình ảnh, âm thanh và video. Đồng thời, các mô hình nhúng đa phương thức từ các nhà cung cấp như Voyage AI và Cohere cho phép nhúng kết hợp giữa hình ảnh và văn bản trong cùng một không gian vector.
Bài viết này hướng dẫn bạn cách xây dựng một ứng dụng RAG (Retrieval Augmented Generation) mới, sử dụng dữ liệu kiến thức đầu vào đa phương thức với văn bản, hình ảnh và bảng biểu đan xen nhau. Toàn bộ quy trình bao gồm phân tích khái niệm đa phương thức, xử lý dữ liệu đa phương thức cho truy xuất, đánh giá các mô hình nhúng đa phương thức và phát triển ứng dụng triển khai thực tế sử dụng MongoDB Atlas Vector Search kết hợp các mô hình của Voyage AI và Google Gemini.
Giới Thiệu Về Đa Phương Thức trong AI
Đa Phương Thức là gì?
Đa phương thức (multimodality) trong AI đề cập đến khả năng của các mô hình máy học xử lý, hiểu và tạo ra các loại dữ liệu khác nhau như văn bản, hình ảnh, âm thanh, video,... trong cùng một hệ thống.
Các mô hình nhúng đa phương thức có thể nhận đầu vào là nhiều loại dữ liệu khác nhau và ánh xạ chúng vào cùng một không gian vector chiều cao. Các LLM đa phương thức còn có thể tạo ra đầu ra đa dạng, bao gồm nhiều phương thức khác nhau. Tuy nhiên, khi lựa chọn mô hình, cần kiểm tra kỹ các loại dữ liệu mà mô hình hỗ trợ để đảm bảo phù hợp với mục đích triển khai.
Thách Thức Của Đa Phương Thức trong Ứng Dụng RAG
Kiến trúc RAG truyền thống với dữ liệu văn bản
Thông thường, pipeline RAG với dữ liệu thuần văn bản hoạt động theo các bước:
- Tách tài liệu lớn thành các đoạn nhỏ (chunk).
- Mỗi đoạn được nhúng thành vector sử dụng mô hình nhúng văn bản.
- Lưu trữ vector cùng nội dung đoạn text trong cơ sở dữ liệu vector.
- Khi có truy vấn, truy vấn cũng được nhúng vào vector không gian.
- Tìm kiếm vector tương tự để lấy về các đoạn liên quan.
- Kết hợp truy vấn và kết quả truy xuất gửi vào LLM để tạo phản hồi.
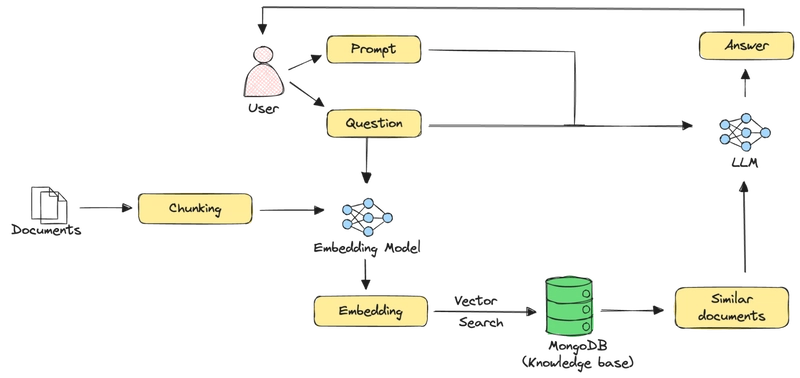
Tuy nhiên, phương pháp này không hiệu quả với dữ liệu đa phương thức như văn bản lẫn hình ảnh, bảng biểu và các yếu tố phi văn bản. Cần phát triển các kỹ thuật mới cho việc phân đoạn tài liệu, lựa chọn mô hình nhúng đa phương thức để duy trì liên hệ bối cảnh giữa các loại dữ liệu khác nhau.
So Sánh Kiến Trúc Mô Hình Nhúng Đa Phương Thức: CLIP và VLM
Mô hình CLIP
Mô hình nhúng đa phương thức phổ biến trước đây dựa trên kiến trúc CLIP (Contrastive Language–Image Pre-training) của OpenAI. CLIP sử dụng hai mạng riêng biệt để nhúng hình ảnh và văn bản, sau đó ánh xạ vào cùng không gian vector.
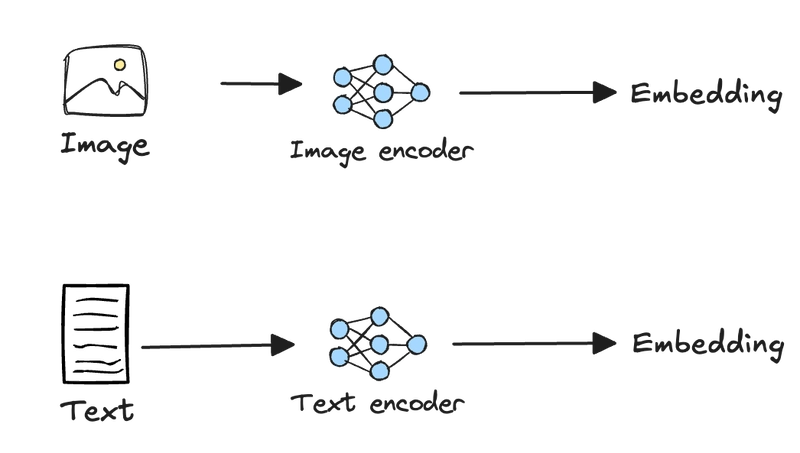
Phân tách này tạo ra bộ xử lý phức tạp để trích xuất thành phần, dẫn đến hiện tượng “modality gap” - khoảng cách phương thức, khiến các vector của cùng nhóm phương thức gần nhau hơn mặc dù không liên quan, và các phương thức khác nhau có thể bị xa lệch nhau trong không gian vector.
Mô hình nhúng dựa trên Vision Language Models (VLM)
Để khắc phục nhược điểm trên, mô hình hiện đại sử dụng một bộ mã hóa transformer thống nhất cho cả hình ảnh và văn bản, tạo ra các biểu diễn đồng nhất giữ mối quan hệ ngữ cảnh giữa các phương thức.
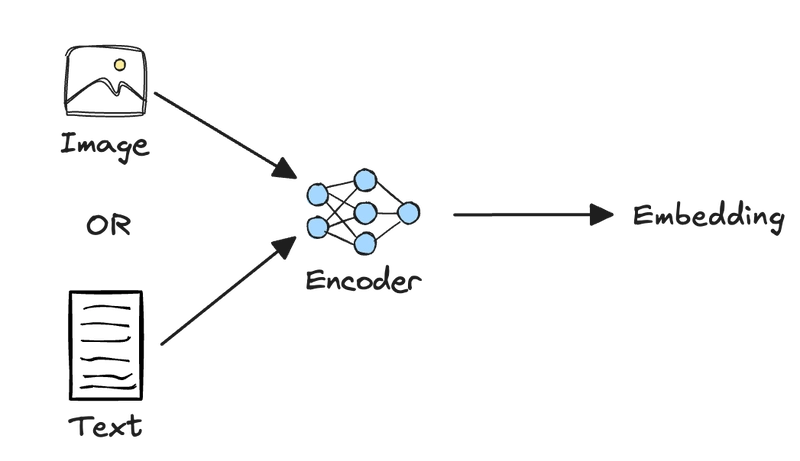
Điều này giảm thiểu khoảng cách phương thức và đơn giản hóa quy trình trích xuất dữ liệu phức tạp, cho phép xử lý trực tiếp các tài liệu có giao thoa văn bản và hình ảnh, ảnh chụp màn hình, PDF có bố cục phức tạp, hình ảnh được chú thích,...
Quy Trình Xây Dựng Ứng Dụng RAG Đa Phương Thức
Kiến trúc tổng thể
Hệ thống sử dụng MongoDB làm bộ lưu trữ vector, mô hình nhúng đa phương thức voyage-multimodal-3 của Voyage AI và mô hình LLM đa phương thức Gemini 2.0 Flash của Google.
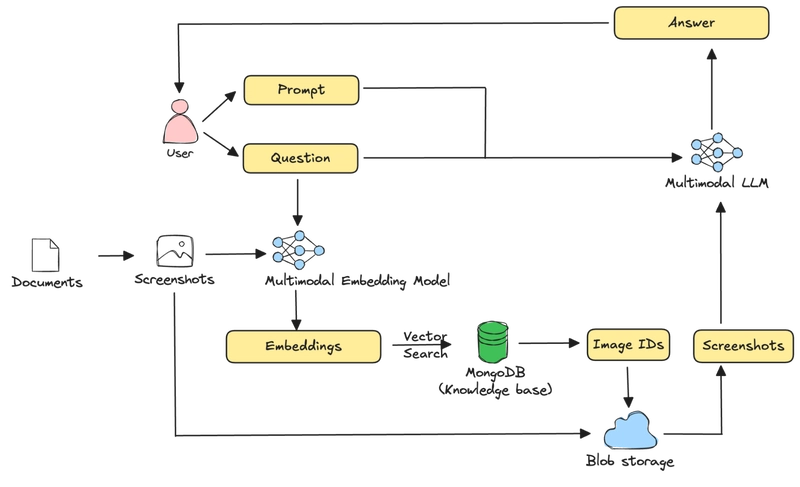
Quy trình bao gồm:
- Chụp ảnh từng trang PDF thành hình ảnh và lưu trữ trên Google Cloud Storage (GCS).
- Nhúng các ảnh này dùng voyage-multimodal-3, lưu vector embedding cùng metadata vào MongoDB.
- Với truy vấn người dùng, embedding truy vấn, thực hiện tìm kiếm vector để lấy các trang liên quan.
- Gửi ảnh cùng truy vấn đến LLM Gemini tạo câu trả lời.
Mã nguồn mẫu có sẵn
Các Bước Triển Khai Chi Tiết
Bước 1: Cài đặt thư viện cần thiết
Bước 2: Thiết lập môi trường
- Tạo tài khoản và cluster MongoDB Atlas, lấy chuỗi kết nối.
- Đăng ký và lấy API key từ Voyage AI và Google Gemini.
- Cấu hình ứng dụng Default Credentials cho Google Cloud Storage.
Bước 3: Đọc PDF từ URL
Dùng PyMuPDF để tải và mở file PDF (ví dụ tải bài báo Deepseek-R1):
Bước 4: Chuyển đổi trang PDF thành ảnh và lưu vào GCS
Mỗi trang được render thành ảnh PNG, lưu vào bucket trên GCS, metadata được trích xuất để lưu MongoDB.
Bước 5: Tạo embeddings đa phương thức
Nhúng ảnh dùng mô hình voyage-multimodal-3 và CLIP (clip-ViT-B-32), lưu embedding vào tài liệu MongoDB.
Bước 6: Ghi dữ liệu vào MongoDB
Module pymongo giúp nhập hàng loạt tài liệu gồm metadata và embeddings vào bộ sưu tập con "multimodal_rag".
Bước 7: Tạo chỉ mục tìm kiếm vector
Tạo index vector trên trường embeddings với số chiều và loại giống nhau (cosine similarity).
Bước 8: Truy vấn và tải ảnh từ GCS
Xây dựng hàm tìm kiếm vector, trả về các khóa GCS tương ứng, từ đó tải và hiển thị ảnh.
Bước 9: Triển khai mô hình LLM đa phương thức
Sử dụng Gemini 2.0 Flash để nhận ảnh và truy vấn, tạo phản hồi dựa trên các ngữ cảnh ảnh đã tìm được.
Bước 10: Đánh giá chất lượng truy xuất và sinh
- Tạo tập câu hỏi kiểm thử dựa trên nội dung tài liệu.
- Đánh giá thuật toán bằng các chỉ số Mean Reciprocal Rank (MRR), mean recall, và sử dụng Gemini làm "trọng tài" chấm điểm chuẩn độ tương đồng câu trả lời.
- Kết quả cho thấy mô hình VLM voyage-multimodal-3 vượt trội CLIP trong cả truy xuất và sinh câu trả lời.
Chỉ số | voyage-multimodal-3 | clip-ViT-B-32 |
|---|---|---|
MRR | Cao hơn | Thấp hơn |
Mean Recall | Cao hơn | Thấp hơn |
LLM Judge Score | 4.5 | 3.8 |
Kết Luận
Multimodality mở ra một giai đoạn mới cho AI khi có thể xử lý và sinh nội dung đa dạng cả văn bản, hình ảnh, âm thanh và video. Xây dựng ứng dụng RAG đa phương thức đòi hỏi các kỹ thuật và mô hình nhúng chuyên biệt để tận dụng tối đa dữ liệu hỗn hợp với hiệu quả cao.
Bài viết đã trình bày chi tiết quy trình thực hiện ứng dụng RAG đa phương thức sử dụng MongoDB Atlas Vector Search và các mô hình Journey AI mới nhất. Qua đó, so sánh kiến trúc CLIP và VLM giúp bạn hiểu rõ ưu nhược điểm cũng như cách đánh giá sản phẩm thực tế. Mong rằng tutorial này sẽ hữu ích cho bạn trong việc phát triển các ứng dụng AI đa phương thức phức hợp.
Để tìm hiểu thêm, bạn có thể truy cập AI Learning Hub của MongoDB hoặc mã nguồn tại Gen AI Showcase GitHub repository .
Tham Khảo
- OpenAI CLIP Paper: https://arxiv.org/abs/2103.00020
- Modality Gap Paper: https://arxiv.org/abs/2203.02053
- Voyage AI Docs Authentication: https://docs.voyageai.com/docs/api-key-and-installation#authentication-with-api-keys
- MongoDB Atlas: https://www.mongodb.com/cloud/atlas/register
- PyMuPDF Documentation: https://pymupdf.readthedocs.io/en/latest/
- Gemini API Reference: https://aistudio.google.com/app/api
- Gen AI Showcase GitHub: https://github.com/mongodb-developer/GenAI-Showcase
Loading...