
Trọn Bộ 50 Câu Hỏi Phỏng Vấn Kỹ Thuật 'Nặng Ký' về Generative AI cho Data Scientist Cấp Cao
0
50 Câu Hỏi & Trả Lời Chuẩn Bị Phỏng Vấn Kỹ Thuật Về Generative AI Dành Cho Senior Data Scientist
Mở Đầu
Trong bối cảnh trí tuệ nhân tạo (AI) ngày càng phát triển và ứng dụng rộng rãi, lĩnh vực Generative AI (AI tạo sinh) trở thành một trong những mảng nghiên cứu và ứng dụng nổi bật nhất. Đặc biệt đối với các chuyên gia kỳ cựu như senior data scientists, việc cập nhật kiến thức sâu rộng và chuẩn bị kỹ càng cho các cuộc phỏng vấn kỹ thuật liên quan đến Generative AI là vô cùng quan trọng.
Bài viết này cung cấp 50 câu hỏi và câu trả lời chi tiết về các khía cạnh then chốt trong lĩnh vực Generative AI, nhằm hỗ trợ các ứng viên chuẩn bị hiệu quả cho các phỏng vấn công việc ở cấp độ cao. Nội dung bao gồm từ kiến thức cơ bản của Transformer, các mô hình lớn (LLM), kỹ thuật huấn luyện nâng cao, các mô hình đa phương thức, tới hạ tầng và kỹ thuật triển khai.
I. Transformer Cơ Bản
1. Kiến trúc chính của Transformer gồm những thành phần nào và nó vượt qua hạn chế của RNN/LSTM ra sao?
Transformer là một mô hình xử lý tuần tự, nổi bật với khả năng xử lý song song và nắm bắt được mối quan hệ dài hạn trong chuỗi dữ liệu. Nó khắc phục hạn chế về hiệu suất và khả năng bắt mạch dài của RNN/LSTM bằng:
- Self-Attention (Tự chú ý): Đánh giá mối liên hệ giữa mọi token trong chuỗi, tạo biểu diễn ngữ cảnh phong phú.
- Multi-Head Attention (Chú ý đa đầu): Thực hiện song song nhiều phép self-attention, cho phép mô hình học được các đặc trưng khác nhau.
- Position-wise Feed Forward Network: Mạng nơ-ron kết nối đầy đủ, xử lý từng token độc lập sau lớp attention.
- Add & Norm: Kết hợp kết nối dư và chuẩn hóa để ổn định quá trình học.
- Positional Encoding: Bổ sung thông tin vị trí token vào vector đầu vào, giúp duy trì thứ tự chuỗi.
Transformer cho phép huấn luyện song song với khả năng nhớ dài hạn vượt trội so với RNN, làm tăng hiệu suất và khả năng mô hình hóa các quan hệ phức tạp trong dữ liệu tuần tự.

2. Self-Attention hoạt động thế nào? Vai trò của query, key, value ra sao?
Ở self-attention, mỗi token sẽ được biến đổi thành ba vector:
- Query (Q): Dùng để hỏi mức độ liên quan với các token khác.
- Key (K): Biểu diễn các đặc trưng được so sánh với query.
- Value (V): Chứa thông tin cần lấy ra cho token hiện tại.
Quá trình tính attention:
- Tính điểm tương đồng giữa Q và K (dot product).
- Chia điểm tương đồng này cho căn bậc hai kích thước key để chuẩn hóa.
- Áp dụng softmax để chuyển thành phân phối trọng số.
- Dùng trọng số này để tính trung bình có trọng số các value, tạo ra biểu diễn mới cho token.
3. Multi-Head Attention khác gì Single-Head Attention? Lợi ích là gì?
- Multi-Head Attention (MHA) thực hiện đồng thời nhiều self-attention riêng biệt (các "head").
- Mỗi head học các mối quan hệ từ một góc nhìn khác nhau (ví dụ: cú pháp, ngữ nghĩa).
- Kết hợp các đầu lại giúp mô hình nắm bắt thông tin phức tạp hơn.
MHA gia tăng khả năng biểu diễn và sức mạnh học của mô hình qua việc khai thác đa dạng các mức độ ngữ cảnh.
4. Tại sao cần Positional Encoding? So sánh phương pháp tuyệt đối và tương đối?
Self-attention không nhận biết vị trí token tự nhiên, nên positional encoding giúp truyền đạt thứ tự:
- Absolute Positional Encoding: Gán mã vị trí cố định cho từng vị trí token (sử dụng hàm sin, cos hoặc embedding học được).
- Relative Positional Encoding: Mã hóa mối quan hệ khoảng cách giữa token thay vì vị trí tuyệt đối. Ví dụ:
- RoPE: dùng phép quay vector embedding tương ứng vị trí token.
- ALiBi: thêm bias tỷ lệ thuận với khoảng cách vào điểm attention.
Relative encoding thường có tính tổng quát hóa tốt hơn trên các chuỗi dài.
5. Phân biệt Encoder-only (BERT), Decoder-only (GPT) và Encoder-Decoder (T5)
Kiến trúc | Đặc điểm chính | Ứng dụng điển hình |
|---|---|---|
Encoder-only | Xử lý toàn bộ chuỗi đầu vào, học biểu diễn bối cảnh hai chiều | Phân loại văn bản, trích xuất thông tin, QA |
Decoder-only | Sinh văn bản một chiều, tự hồi quy (autoregressive) | Sinh văn bản, chatbot, tạo tóm tắt |
Encoder-Decoder | Kết hợp hai mô-đun, encode input, decode output | Dịch máy, tóm tắt, chuyển đổi chuỗi |
6. Hạn chế tính toán của Transformer chuẩn và các kỹ thuật khắc phục?
- Transformer chuẩn có độ phức tạp tính toán và bộ nhớ O(N²) với N là chiều dài chuỗi, gây tốn kém tài nguyên khi xử lý chuỗi dài.
Các giải pháp:
- Sparse Attention: Chỉ tập trung attention vào một số token cần thiết.
- Efficient/Linearized Attention: Áp dụng các xấp xỉ toán học để giảm chi phí tính toán.
- FlashAttention: Tối ưu truy cập bộ nhớ, tăng tốc độ và giảm dung lượng.
- Các mô hình thay thế: State space models, Reformer, Longformer.
II. Kiến Trúc LLM Nâng Cao và Các Khái Niệm
7. Định nghĩa của Scaling Laws như Kaplan, Chinchilla? Ý nghĩa trong phân bổ tài nguyên?
Scaling Laws chỉ ra quan hệ tỷ lệ giữa kích thước mô hình, lượng dữ liệu, và chi phí tính toán với hiệu năng. Nghiên cứu của Chinchilla cho thấy:
- Hiệu quả tốt nhất khi cân bằng giữa số lượng tham số và dữ liệu huấn luyện.
- Tăng dữ liệu đôi khi hiệu quả hơn tăng kích thước mô hình trong giới hạn tài nguyên cố định.
8. Khả năng emergent của LLM là gì? Ví dụ thực tế?
Emergent Capabilities là các khả năng xuất hiện bất ngờ khi mô hình vượt quá kích thước nhất định, không dự đoán được từ các mô hình nhỏ hơn. Ví dụ:
- Giải toán đa bước.
- Hiểu và thực hiện câu lệnh phức tạp mà không cần fine-tuning.
- Tạo mã code chính xác ở mức độ chưa từng thấy ở mô hình nhỏ hơn.
9. Mixture of Experts (MoE) là gì? So sánh với dense model?
- MoE: Một mô hình gồm nhiều "chuyên gia" nhỏ, mỗi token chỉ kích hoạt một số chuyên gia thích hợp. Giúp mở rộng quy mô mô hình mà không tăng chi phí tính toán tương ứng.
- Dense model: Tất cả tham số được tính cho mỗi token.
Đặc điểm | MoE | Dense Model |
|---|---|---|
Quy mô | Rất lớn (tỷ lệ chuyên gia đa dạng) | Giới hạn bởi hiệu năng thiết bị |
Tính toán | Chỉ dùng một số chuyên gia | Tính toàn bộ tham số |
Ưu điểm | Tiết kiệm FLOPS, mở rộng mô hình | Ổn định, đơn giản |
Nhược điểm | Phức tạp huấn luyện, overhead routing | Tốn tài nguyên khi lớn |

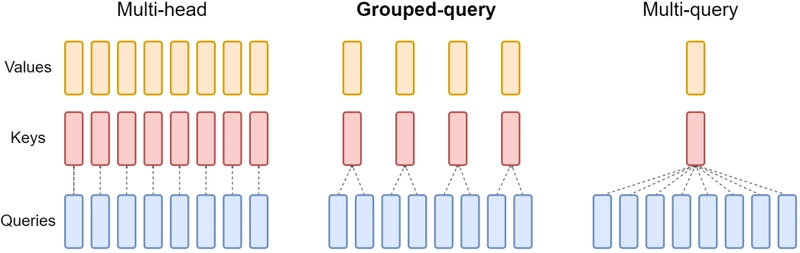
10. KV Caching, Multi-Query Attention và Grouped-Query Attention cải thiện hiệu suất thế nào?
- KV Caching: Lưu trữ key và value từ các bước trước để tái sử dụng, tránh tính toán lại trong quá trình tạo văn bản.
- Multi-Query Attention (MQA): Chia sẻ key và value cho tất cả các head, giảm bộ nhớ lưu trữ KV.
- Grouped-Query Attention (GQA): Giữa MQA và Multi-Head Attention, chia query head thành nhóm, mỗi nhóm chia sẻ key và value.
Các kỹ thuật này giúp giảm sử dụng bộ nhớ và tăng tốc độ tính toán trong giai đoạn inference.
III. Kỹ Thuật Huấn Luyện Nâng Cao và Fine-tuning
11. Tác động của dữ liệu, tiền xử lý và tokenizer (BPE) tới huấn luyện và hiệu năng LLM?
- Dữ liệu sạch, đa dạng, không trùng lặp đảm bảo mô hình học được kiến thức chính xác, giảm overfitting.
- Tokenization (BPE): Tách từ thành subword giúp cân bằng hiệu quả bộ nhớ và khả năng biểu diễn ngôn ngữ hiếm.
- Lựa chọn từ vựng lớn giúp giảm chiều dài chuỗi, nhưng tăng kích thước embedding (tradeoff nhớ).
12. Các kỹ thuật ổn định huấn luyện transformers lớn?
- Warm-up và learning rate scheduling: Tránh update quá lớn giai đoạn đầu.
- Gradient clipping: Ngăn ngừa gradient explosion.
- Optimizers: AdamW thường hiệu quả hơn Adam + L2.
- Layer normalization: Ổn định tín hiệu qua các lớp.
- Mixed precision (BF16, FP16): Tăng tốc với hỗ trợ phần cứng.
- Khởi tạo trọng số hợp lý.
13. Instruction tuning khác gì so với supervised fine-tuning; Reject Sampling là gì?
- SFT: Finetune với cặp input-output chuẩn.
- Instruction tuning: Dữ liệu tập trung vào chỉ dẫn (instruction) và phản hồi theo lệnh, giúp mô hình hiểu dạng câu lệnh đa dạng.
- Rejection Sampling: Chọn lọc các câu trả lời tốt nhất từ các mẫu sinh ra bởi mô hình hoặc feedback để dùng trong tập huấn luyện fine-tuning.
14. So sánh RLHF, RLAIF, DPO và GRPO?
Phương pháp | Mô tả chính | Ưu điểm | Nhược điểm |
|---|---|---|---|
RLHF (Reinforcement Learning Human Feedback) | RL dựa trên reward model học từ đánh giá của con người | Chính xác, phản ánh đúng ý người | Tốn kém, phức tạp |
RLAIF (RL from AI Feedback) | Thay con người bằng AI đánh giá | Mở rộng, tiết kiệm chi phí | Phụ thuộc chất lượng AI đánh giá |
DPO (Direct Preference Optimization) | Học trực tiếp từ dữ liệu ưu tiên, không dùng reward model | Đơn giản, ổn định | Hiệu quả có thể thấp hơn RLHF |
GRPO (Group Relative Policy Optimization) | So sánh nhóm kết quả không cần reward hay value model | Tiết kiệm tài nguyên, dễ mở rộng | Mới, cần tối ưu nhiều |

15. Các lưu ý khi thiết kế Reward Model cho RLHF?
- Đảm bảo chất lượng và đa dạng dữ liệu phản hồi.
- Học được mức độ ưu tiên (degree of preference).
- Calibration điểm số để phản ánh chính xác sở thích con người.
- Giảm thiểu hiện tượng "Reward hacking" (mô hình tối ưu reward sai lệch).
- Cân bằng giữa generalization và overfitting.
16. Sự khác biệt giữa RLHF và RLVR, và ứng dụng DeepSeek-R1?
- RLHF: Sử dụng feedback dựa trên sự đánh giá chủ quan của con người.
- RLVR: Dùng reward rõ ràng, có thể kiểm chứng (ví dụ: đúng mã nguồn chạy, đúng số liệu toán học).
- DeepSeek-R1 tập trung vào sử dụng RLVR (đặc biệt trong nâng cao khả năng suy luận) kết hợp với RLHF để tinh chỉnh khả năng tương tác và tính chính xác.
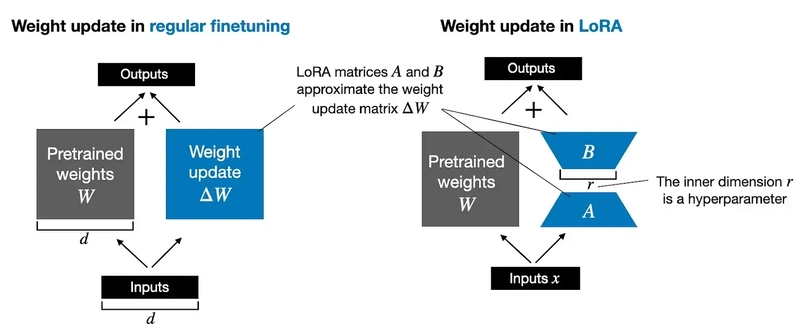
17. LoRA/QLoRA là gì? Tại sao dùng? QLoRA giải quyết vấn đề nào?
- LoRA: PEFT bằng cách chèn adapter đáy thấp (low-rank) vào mạng và chỉ học adapter.
- QLoRA: Mở rộng LoRA bằng kỹ thuật lượng tử hóa 4-bit giảm tối đa bộ nhớ khi tải mô hình lớn, vẫn giữ độ chính xác.
- Giúp fine-tuning trên thiết bị có bộ nhớ hạn chế.
18. Mục đích và kỹ thuật model merging (Task Arithmetic, SLERP)?
- Kết hợp nhiều mô hình fine-tuned để tạo mô hình đa năng mà không cần huấn luyện lại.
- Task Arithmetic: Cộng/trừ vector độ lệch các tham số của các model.
- SLERP: Interpolation trên mặt cầu tham số, tránh interpolation tuyến tính gây méo biểu diễn.
IV. Tìm Kiếm Tăng Cường Sinh (RAG)
19. Thành phần chính của RAG? Khi nào ưu tiên RAG hơn fine-tuning?
- Thành phần: retriever (tìm kiếm), knowledge base, generator (LLM).
- RAG ưu tiên khi cần:
- Thông tin cập nhật, lớn, không thể lưu toàn bộ trong mô hình.
- Giảm hiện tượng nhảm (hallucination).
- Truy cập chính xác dữ liệu ngoài suốt.
Fine-tuning phù hợp khi cần thay đổi cấu trúc, phong cách hoặc khả năng tổng quát của mô hình.
20. So sánh các loại tìm kiếm: lexical, semantic, hybrid
Loại tìm kiếm | Cách hoạt động | Ưu điểm | Khuyết điểm |
|---|---|---|---|
Lexical | So khớp từ khóa (TF-IDF, BM25) | Nhanh, hiệu quả truy vấn chính xác | Không bắt được ý nghĩa đồng nghĩa |
Semantic | Embedding vector, tìm gần nhau | Bắt được câu tương tự, đa dạng hơn | Tốn tài nguyên, phụ thuộc embedding |
Hybrid | Kết hợp 2 cách trên | Cân bằng ưu, nhược điểm | Phức tạp, tốn công tuning |
21. Các chỉ số đánh giá RAG?
- Precision và Recall của Retriever: Độ đúng/số lượng thông tin liên quan tìm thấy.
- Faithfulness: Đáp án chính xác theo thông tin.
- Answer Relevancy: Đáp ứng câu hỏi ra sao.
- Đánh giá end-to-end với dữ liệu chuẩn.
22. Các kỹ thuật nâng cao RAG (HyDE, Re-ranking, Iterative Retrieval)?
- HyDE: Sinh văn bản giả định trước để cải thiện embedding tìm kiếm.
- Re-ranking: Lọc lại kết quả tìm kiếm ban đầu với mô hình đánh giá chính xác hơn.
- Iterative retrieval: Tìm kiếm nhiều vòng dựa trên câu trả lời trước đó.
V. Mô Hình Đa Phương Thức
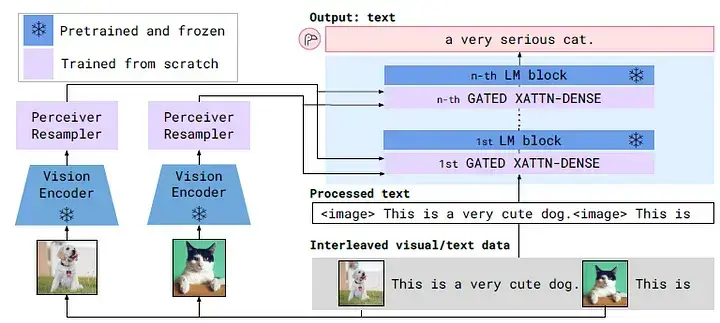
23. Mô hình đa phương thức kết hợp hình ảnh và text thế nào (ví dụ CLIP, Flamingo, LLaVA)?
- CLIP: Tạo embedding văn bản và ảnh trong không gian chung, dùng contrastive learning.
- Flamingo: Dùng cross-attention giữa text và visual token, kết hợp thông tin trực tiếp.
- LLaVA: Input-level fusion, gộp các token đặc trưng ảnh vào chuỗi token văn bản, mô hình hóa cùng một lúc.
24. Khó khăn chính khi huấn luyện mô hình đa phương thức?
- Dữ liệu đồng bộ lớn, chất lượng cao.
- Chi phí tính toán cao.
- Khó thiết kế cơ chế fusion hiệu quả.
- Vấn đề đánh giá kết quả đa chiều.
VI. Mô Hình Sinh Ảnh và Diffusion
25. Nguyên lý cơ bản của Diffusion Model và Latent Diffusion Model?
- Diffusion Model: được huấn luyện để "dọn sạch" dần tiếng ồn từ dữ liệu, ngược chiều quá trình nhiễu.
- Latent Diffusion Model: thực hiện diffusion trong không gian latent, giảm chi phí tính toán và tăng hiệu quả.

26. Diffusion Transformer khác gì U-Net trong diffusion models?
- Transformer dùng attention cho xử lý patch ảnh, dễ mở rộng quy mô.
- U-Net dùng convolution, tận dụng cấu trúc không gian ảnh.
- DiT có khả năng mở rộng tốt nhưng chi phí hơn, mất một số inductive bias.
27. Classifier-Free Guidance là gì? Hoạt động ra sao?
- Kỹ thuật tăng trọng số phần điều kiện trong dự đoán noise mà không cần Bộ phân loại tách biệt.
- Điều chỉnh scale để cân bằng tính đa dạng và mức độ trung thành với prompt.
28. So sánh các sampler DDIM, DPM-Solver về tốc độ và chất lượng?
Sampler | Tốc độ | Chất lượng |
|---|---|---|
DDIM | Trung bình | Tốt với bước lớn |
DPM-Solver | Nhanh hơn nhiều | Chất lượng cao, ít bước hơn |
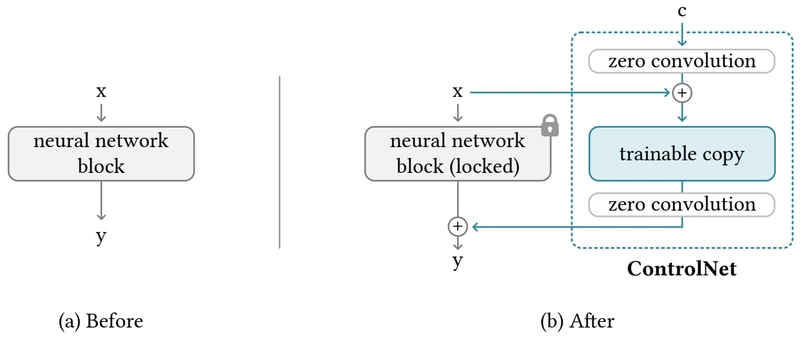
29. ControlNet là gì và làm sao điều khiển được hình ảnh sinh?
- Module thêm vào pretrained diffusion model để bổ sung điều kiện không gian như dạng edge, pose...
- Giữ frozen model, chỉ học thêm mạng encoder bản sao.
- Zero convolution giúp chèn từ từ ảnh điều kiện.
30. Các kỹ thuật fine-tuning đặc thù cho image generation?
- Full fine-tuning: Huấn luyện toàn bộ model, tốn kém.
- LoRA: Cập nhật adapter nhỏ, hiệu quả.
- DreamBooth: Fine-tuning với số ít ảnh cá nhân hoá.
- Textual Inversion: Chỉ học embedding mới, nhẹ nhất.
Cần tránh overfitting và catastrophic forgetting khi fine-tuning, cân bằng mức độ tùy biến và khả năng tổng quát hóa.
VII. Hạ Tầng và Kỹ Thuật Foundation Model
31. Giải thích Data Parallelism, Tensor Parallelism và Pipeline Parallelism?
- Data Parallelism: Nhân bản model, mỗi GPU học một phần batch.
- Tensor Parallelism: Phân chia ma trận trọng số và phép tính trên các GPU.
- Pipeline Parallelism: Chia model thành các phần liên tục trên GPU khác nhau, xử lý tuần tự.
Thực tế kết hợp cả ba để đào tạo mô hình rất lớn.

32. ZeRO 1,2,3 là gì? Giảm dung lượng như thế nào?
- ZeRO 1: Phân phối optimizer states.
- ZeRO 2: Phân phối thêm gradient.
- ZeRO 3: Phân phối hoàn toàn các tham số, chỉ tải phần cần thiết.
Giảm thiểu bộ nhớ trùng lặp giúp train mô hình rất lớn hiệu quả hơn.
33. So sánh PTQ và QAT trong Quantization? GPTQ & AWQ là gì?
- PTQ (Post Training Quantization): Áp dụng sau khi huấn luyện, nhanh nhưng mất độ chính xác.
- QAT (Quantization Aware Training): Giả lập quantization trong quá trình huấn luyện, chính xác hơn nhưng tốn kém.
- GPTQ: Kỹ thuật PTQ nâng cao đặc biệt cho các LLM, giảm lỗi quantization.
- AWQ: Phiên bản cải tiến của GPTQ nhằm giảm lỗi và cải thiện hiệu quả.
34. Speculative Decoding tăng tốc giải mã LLM thế nào?
Dùng mô hình nhỏ để dự đoán nhóm token trước, mô hình chính kiểm tra một lần cho cả nhóm thay vì từng token, tăng tốc phân lớp từ 2-4 lần.
35. FlashAttention tối ưu attention ra sao?
Sử dụng bộ nhớ SRAM nhanh trong GPU, tính toán từng block nhỏ tránh swap ngoài vào RAM chính, giảm IO và tăng tốc độ.
36. ONNX và TensorRT có vai trò gì khi deploy?
- ONNX: Định dạng chuẩn chuyển model giữa framework, cho phép tối ưu.
- TensorRT: Thư viện tối ưu hoá inference rất hiệu quả trên NVIDIA GPU, tăng tốc, giảm độ trễ.
VIII. Phần Inference, Prompting và Agent
37. In-Context Learning hiệu quả với kích thước mô hình ra sao?
Kích thước lớn hơn mô hình, lượng training nhiều hơn rất quyết định khả năng "học trong ngữ cảnh" – tức là hiểu và thực thi nhiệm vụ qua prompt mà không cần fine-tune.
38. Chain-of-Thought (CoT) và Tree-of-Thought (ToT) khác nhau thế nào?
- CoT: Sinh ra chuỗi suy luận tuần tự từng bước.
- ToT: Khám phá nhiều nhánh suy luận song song, đánh giá và cắt nhánh kém hiệu quả.
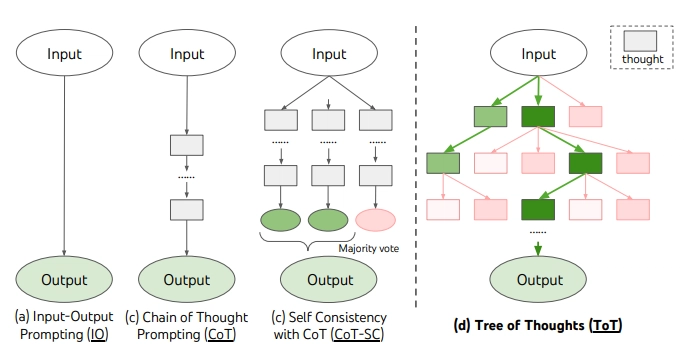
39. Giới hạn nội tại của LLM trong suy luận đa bước là gì?
- Phụ thuộc biểu hiện bề mặt prompt.
- Không có khả năng suy luận logic rõ ràng chắc chắn.
- Dễ xảy ra hallucination.
- Khó hiệu chỉnh lỗi trung gian.
- Giới hạn độ dài context.
40. Phương pháp thúc đẩy lập kế hoạch và ReAct framework là gì?
- Giao việc LLM kế hoạch rồi thực thi theo chu kỳ: suy nghĩ → hành động → quan sát.
- ReAct thêm tương tác với công cụ bên ngoài (search engine, calculator...) qua API.

41. AutoGen, MetaGPT cải thiện gì cho AI Agent?
- Giúp LLM hỗ trợ làm việc nhóm, duy trì trạng thái, học hỏi tự điều chỉnh.
- Tương tác đa tác vụ, gọi công cụ, lập kế hoạch phức tạp.
- Tích hợp cơ chế ghi nhớ dài hạn và hợp tác đa agent.
IX. Đánh Giá và Benchmark
42. Khó khăn trong đánh giá mô hình sinh?
- Kết quả mở, đa dạng, mang tính chủ quan.
- Đa chiều: chất lượng, tính hợp lệ, sự an toàn.
- Không có chỉ số tự động toàn diện.
43. So sánh đánh giá tự động và đánh giá bởi người?
- Tự động: nhanh, chi phí thấp, không sâu sắc.
- Người: chính xác, toàn diện, tốn kém, không đồng nhất.
44. Đánh giá truthfulness dùng benchmark nào?
- TruthfulQA, HaluEval đánh giá khả năng tránh sai lệch, hallucination.
45. Các benchmark đo khả năng suy luận nổi bật?
- MMLU, GSM8K, BIG-Bench, HellaSwag, ARC, DROP, MATH, HumanEval.
46. Đánh giá text-image về prompt alignment, chất lượng, đa dạng ra sao?
- Sử dụng CLIP score cho độ liên quan prompt-image.
- FID cho chất lượng thực tế hình ảnh.
- Đánh giá trực quan đa dạng bằng con người hay metrics bổ sung.
47. Khó khăn khi đánh giá mô hình đa phương thức?
- Đánh giá sự kết hợp thông tin cross-modal.
- Thiếu bộ dữ liệu đánh giá tiêu chuẩn.
- Tính chủ quan cao.
48. Các giới hạn và game hóa benchmark?
- Dữ liệu bị rò rỉ, mô hình học thuộc lòng.
- Tối ưu hóa benchmark quá mức.
- Đánh giá không phản ánh thực tế.
49. Các kỹ thuật giải thích hành vi Transformer?
- Visualization attention.
- Gradient-based saliency.
- Ablation studies.
- Mechanical interpretability.
50. Các nguồn học tập bổ sung?
- Các bài viết chi tiết bằng tiếng Hàn và tiếng Anh của các nhà nghiên cứu hàng đầu.
- Các blog huggingface, medium, arXiv papers...
Kết Luận
Bài viết này tập trung cung cấp 50 câu hỏi và trả lời trọng tâm về Generative AI dành cho senior data scientists. Nội dung bao phủ toàn diện kiến thức từ cơ bản đến nâng cao, giúp bạn chuẩn bị một cách bài bản cho các buổi phỏng vấn kỹ thuật về lĩnh vực này. Qua đó, bạn không chỉ cập nhật các công nghệ mới mà còn hiểu sâu các kỹ thuật huấn luyện, đánh giá và triển khai mô hình AI hiện đại.
Để nâng cao hiệu quả, hãy luyện tập trả lời các câu hỏi theo cách diễn đạt riêng, đồng thời cập nhật thường xuyên các phát triển mới trong lĩnh vực. Chúc bạn thành công trong hành trình chinh phục vị trí senior data scientist trong Generative AI!
Tham Khảo
- Vaswani et al., "Attention is All You Need" (2017), https://arxiv.org/abs/1706.03762
- Kaplan et al., "Scaling Laws for Neural Language Models" (2020), https://arxiv.org/abs/2001.08361
- Fedus et al., "Chinchilla: Training Compute-Optimal Large Language Models" (2022), https://arxiv.org/abs/2203.15556
- Ouyang et al., "Training language models to follow instructions with human feedback" (2022), https://arxiv.org/abs/2203.02155
- Ramesh et al., "Hierarchical Text-Conditional Image Generation with CLIP Latents" (2022), https://arxiv.org/abs/2204.06125
- Ho et al., "Denoising Diffusion Probabilistic Models" (2020), https://arxiv.org/abs/2006.11239
- He et al., "ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models" (2023), https://arxiv.org/abs/2302.05543
- Microsoft DeepSpeed: https://www.deepspeed.ai/
- Huggingface Blog, various: https://huggingface.co/blog
- "Understanding Chain-of-Thought Prompting" (2022), https://arxiv.org/abs/2201.11903
Lưu ý: Để đạt hiệu quả cao, hãy kết hợp học lý thuyết sâu và thực hành coding, thử nghiệm các mô hình thực tế và tham khảo tài liệu cập nhật liên tục từ cộng đồng AI.
Loading...